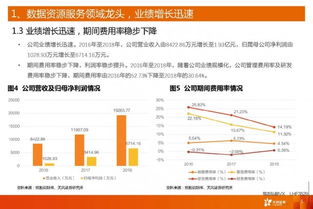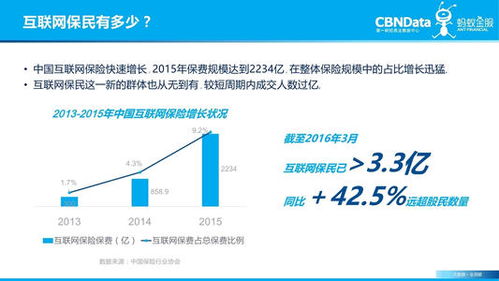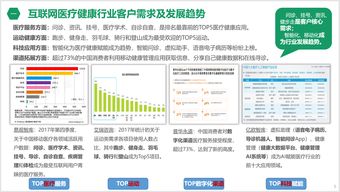
隨著互聯網技術的迅猛發展,醫療健康領域正在經歷一場深刻的數字化轉型。在線智能問診作為服務創新的代表產品,正逐漸改變傳統醫療服務模式,而這一變革的核心在于互聯網平臺建設及其背后強大的數據服務支持。本文將從服務創新、產品實現、平臺建設及數據服務四個維度,探討互聯網智能問診的發展現狀與未來趨勢。
服務創新是在線智能問診的核心理念。傳統的醫療服務受限于時間和空間,患者往往需要排隊候診,耗費大量時間成本。而在線智能問診通過人工智能技術,實現了7×24小時不間斷的醫療服務。患者只需通過手機或電腦,即可隨時隨地進行癥狀咨詢、初步診斷和用藥建議。這種服務模式不僅提高了醫療資源的利用效率,也極大地改善了患者的就醫體驗。
在產品實現層面,智能問診系統融入了自然語言處理、機器學習和醫學知識圖譜等先進技術。系統能夠理解患者的癥狀描述,結合海量醫學數據進行智能分析,給出初步診斷建議。同時,產品設計注重用戶體驗,界面簡潔友好,操作流程便捷,即使是年長用戶也能輕松上手。更重要的是,系統建立了完善的分診機制,對于復雜病癥能夠及時轉接至專業醫生,確保醫療安全。
在互聯網平臺建設方面,需要構建一個穩定、安全、可擴展的技術架構。平臺應當具備高并發處理能力,能夠同時服務大量用戶;同時要保證數據傳輸和存儲的安全性,特別是涉及個人健康信息時,必須符合相關法規要求。平臺還需要建立完善的醫生管理體系和患者服務體系,實現醫患匹配、在線處方、藥品配送等全流程服務。
互聯網數據服務是整個系統的智慧引擎。通過收集和分析用戶的問診數據、癥狀描述、用藥反饋等信息,系統能夠不斷優化診斷算法,提高診斷準確性。這些數據還可以為公共衛生研究提供寶貴資源,幫助醫療機構了解疾病發展趨勢,制定科學的防控策略。同時,數據服務還能實現個性化健康管理,基于用戶的健康狀況提供定制化的健康建議和預防方案。
隨著5G、物聯網等新技術的應用,在線智能問診將更加智能化、個性化。人工智能診斷的準確性將不斷提高,遠程監測設備將與問診平臺深度整合,實現真正的全周期健康管理。同時,數據安全和隱私保護也將成為行業發展的重點議題。
在線智能問診作為互聯網+醫療的典型應用,通過服務創新、產品優化、平臺建設和數據服務的協同發展,正在重塑醫療健康服務的生態格局。這種創新不僅帶來了便利,更重要的是讓優質醫療資源得以更公平地分配,為構建全民健康服務體系提供了新的可能。